
티스토리 뷰
Leader Election
- main server(leader server)와 그 server의 replica들로 다중 server 환경을 구성했을 때
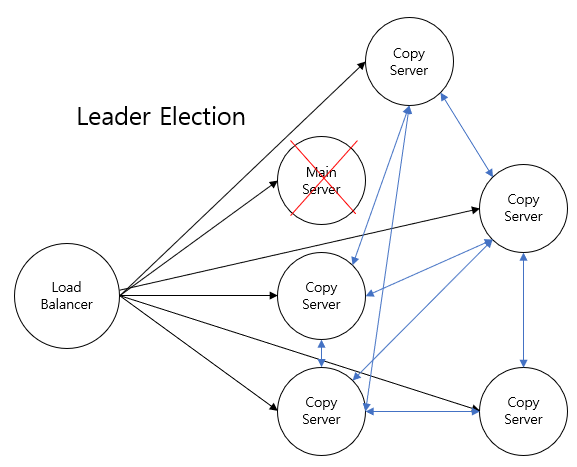
- main server가 다운되면 main server는 자신을 대체할 서버(Leader server)를 찾을 신호를 보낸다.
- 이 신호를 받은 Copy server들은 main server를 대신할 leader server를 선정한다.
- 그 중 가장 latency와 throughput이 적은 server가 Leader server가 되어 일시적으로 main server의 Leadership을 가진다.
- 모든 request는 우선적으로 Leader로 선정된 서버로 간다.
- 어떤 server가 leader가 될지를 결정하는 알고리즘 매우 복잡하고, leader election을 전문적으로 서비스하는 third party 서비스 회사들이 있다.
- 대표적으로 Kafka가 있다.
스케줄링 알고리즘
- 3주차때 Load Balancer의 Scheduling 방식으로 Round Robin, Weighted Round Robin을 살펴보았다.
- 해당 알고리즘은 한 클라이언트가 요청을 보냈을 때, Load Balancer가 어떤 서버로 보낼지 그때그때 다르기 때문에 한계가 있다.
- 특정 client의 요청이 특정 서버만 처리하지 않을 경우 Cache 문제가 생긴다.
- 각 서버마다 Cache를 가지고 있는데, 이 Cache에는 특정 client에만 전송할 데이터가 저장된다고 한다.
- client 요청을 받을때마다 요청을 처리하는 서버가 달라진다면 캐시간 data consistency(일관성)이 훼손될 것이고, Cache에 데이터가 없을 경어 DB조회를 하기 때문에 조회 비용이 생긴다.
- 또한 여러 server의 Cache에 data를 중복하여 저장하기 때문에 불필요한 공간 낭비가 발생한다.
- 이를 극복하기 위해 hashing 방법을 이용할 수 있다.
단순/직접 hashing
사용자를 구분하는 지정된 key를 hash 처리하고 특정 server로 요청을 매핑하여 트래픽을 분배한다.
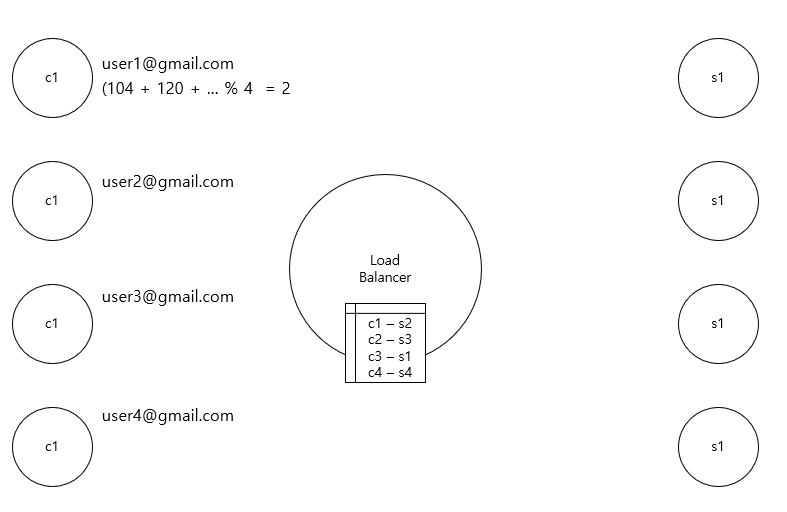
예를 들어, 각 client의 email을 이루는 각 문자를 ascii 문자로 변환하여 그 값을 모두 더하고 server의 수 만큼 나누는 방법을 사용한다. (지정된 key를 moduler function을 통하여 지정된 범위의 숫자로 생성하는 방식).
장점
- hashing scheduling방식은 특정 사용자가 항상 같은 서버로 연결되는 것을 보장한다.
- Cache를 사용할 경우 data consistency를 지키고, DB 조회 비용이 감소하게 된다.
단점
- server수에 의존적: server 추가/제거 시 재계산 및 할당이 필요하다.
- 위의 예시에서 만약 한 server가 다운될 경우 server는 3대가 남게 되는데, 각 key의 server 번호를 찾기위해 모든 hash를 다시 계산해야 하므로 데이터의 위치가 변경된다. 이러한 문제는 서버가 증가할때도 동일하다.
Hash Ring (Consistent Hasing, 일관된 해싱)
- hash ring은 단순 hashing과 달리 서버 수에 독립적으로 작동한다.
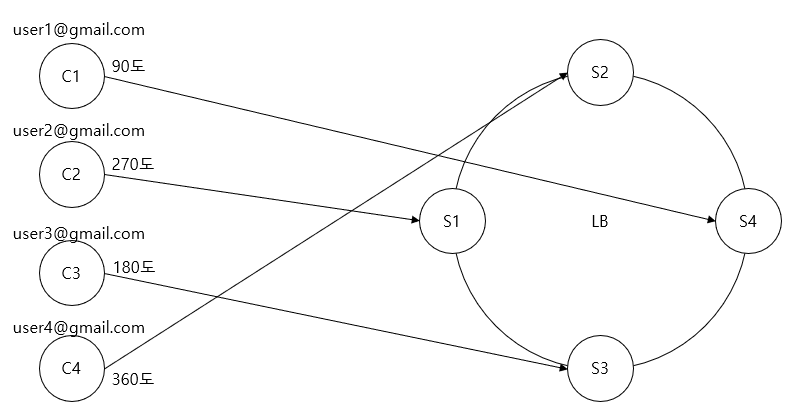
- Server 찾기
- 원 안에서 server를 분배한다
- client의 고유번호를 hasing하여 number를 각도화 한다.
- 서버의 위치와 일치하거나, key hash value가 어떤 server와도 일치하지 않는다면 가장 가까운 서버와 매핑된다.
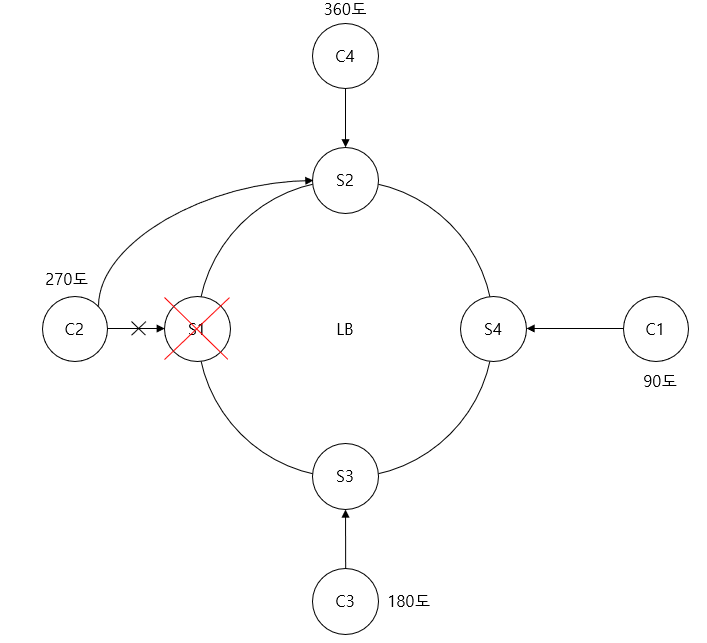
- 특정 Server 다운 시
- 시계방향 인접한 server로 간다.
- 모든 key값을 다시 hash할 필요 없다.
- S1이 감당하던 C2또는 그 이상의 client의 요청들이 모두 S2가 감당해야 되므로 S2의 부하가 높아지는 문제점이 있다.
- 수많은 요청이 한 서버에 몰리지 않도록 server를 원안에 촘촘히 배치한다. server를 많이 배치할수록 위의 문제점은 줄어든다.
Rendezvouz Hasing(랑데부 해싱)
- 단순 해싱방식의 서버 다운시의 비효율성을 문제점을 해결할 수 있는 알고리즘이다.
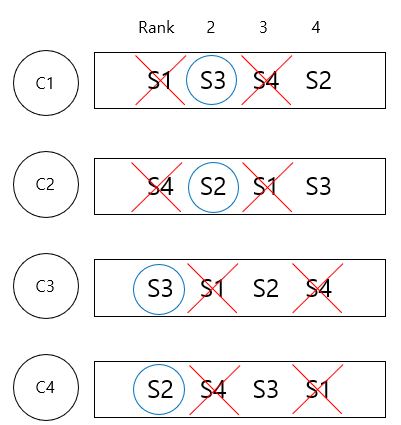
- 각 client에 server1개가 아닌 모든 서버가 우선순위 순서대로 있는 list를 mapping한다.
- 우선순위가 가장 높은 서버가 해당 client의 요청을 처리하고 만약 요청을 처리하던 server가 다운되면 그 다음 우선순위의 server가 해당 client의 요청을 처리한다.

- server1이 다운되면 client1의 요청은 다음 순서인 server3에서 처리된다.
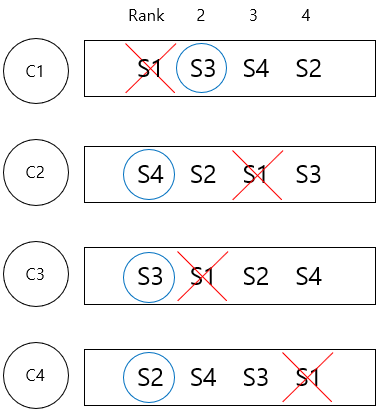
- server4이 다운되면 client2의 요청은 다음 순서인 server2에서 처리된다.
가정) Airbnb 시스템 디자인
Example Question
에어비앤비는 숙소 임대를 중계하는 서비스이다.
만약 에어비앤비 시스템을 디자인한다고 가정해보았다.
만약 신입 개발자라면 팀장님께 어떤 질의를 할 수 있을까?
1. 프로젝트의 scope 정하기
- renter 서비스만 개발할 것인가? (one side) host와 renter 서비스 모두 개발할 것인가? (both side)
2. 각 side마다 feature, functionaliy는 어디까지 만들어야 할까?
- host → create & delete listing
- renter → browse the lists, book, and manage the booking
3. user는 매물을 검색할 때 어떤 기준으로 검색을 해야 할까?
4. 둘 이상의 user가 같은 매물을 보다가 한 user가 예약을 선택 했을 때 나머지 유저들에게 만료되었다고 해야 되지 않을까?
- 만약 예약이 되었을 시 해당 매물은 lock이 되고 lock이 된 상태의 지속시간이 15분이라고 하자.
- 예약 프로세스가 끝나고(processing interval) user가 예약을 확정시켰을 경우 해당 매물은 영구적으로 lock이 되어야 한다.(permanent locking)
5. Host contect, Authentication, Payment (부차적인 기능)이 필요한가?
6. Scale은 어느정도 될것인가?
- user와 listing이 얼마정도 될지 예상하고, 이것을 감당할 시스템을 디자인해야 된다.
7. Availability(가용성)와 Latency(지속성)는 어떻게 될것인가?
- 지역마다 매물 개수는 차이가 있을 것이고 매물이 많거나 적게 있을것이다.
- 이를 충분히 빠르게(fast), 정확하게(accurate), 신뢰도 높게(reliable) 보여주어야 한다.
Storage의 문제
- 50 milion users, 1 milion lists
- list를 저장하려고 한다면, title description, links to photos, unique id가 저장 되어있어야 한다.
- 이 데이터를 SQL에 저장한다고 한다면 지역을 기준으로 검색을 할 때 위도/경도를 계산하는 알고리즘을 이용하여 조회를 해야 할것이다.
- 하나의 매물마다 계산을 해야 되기 때문에 알고리즘의 시간복잡도는 O(N)이 된다.
- 더 효율적인 탐색을 위해 Tree DB라는 Storage를 사용한 알고리즘이 있다.
- 자식 노드가 4개로 이루어진 트리 형태의 자료구조이며, 지도를 4분할하여 분할된 위치로 계속 이동하며 탐색한다.
Quad Tree
단순하게 지도의 좌측 최상단부터 우측 최후단까지 차례대로 탐색한다고 했을 때, 최악의 경우 목적지가 우측 최후단에 있을때 탐색 시간이 어마어마하게 걸릴 것이다.
Quad Tree 알고리즘은 이러한 비효율성을 극복할 수 있다.
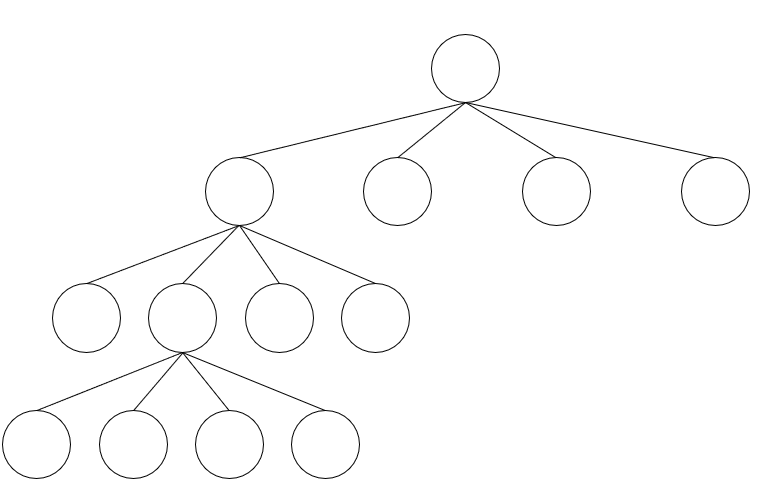
- 공간을 4개의 자식 노드로 분할하여 recursition으로 풀어 나가는 알고리즘이다.
3D 데이터를 표현하기 위한 자료구조를 Scene Graph라고 한다. 여기에 자식 노드가 2개인 Binary Tree,
4개인 Quad Tree, 8개인 OcTree가 있다. Quad Tree는 상하 개념이 없어서 3차원 세계를 4개의 평면으로 분할한다.
OcTree는 4개로 분할한 Quad Tree에서 상하의 분할 평면으로 나누어 총 8개의 자식 노드를 갖게된다.
지형을 표현할 때 사용될 수 있다.
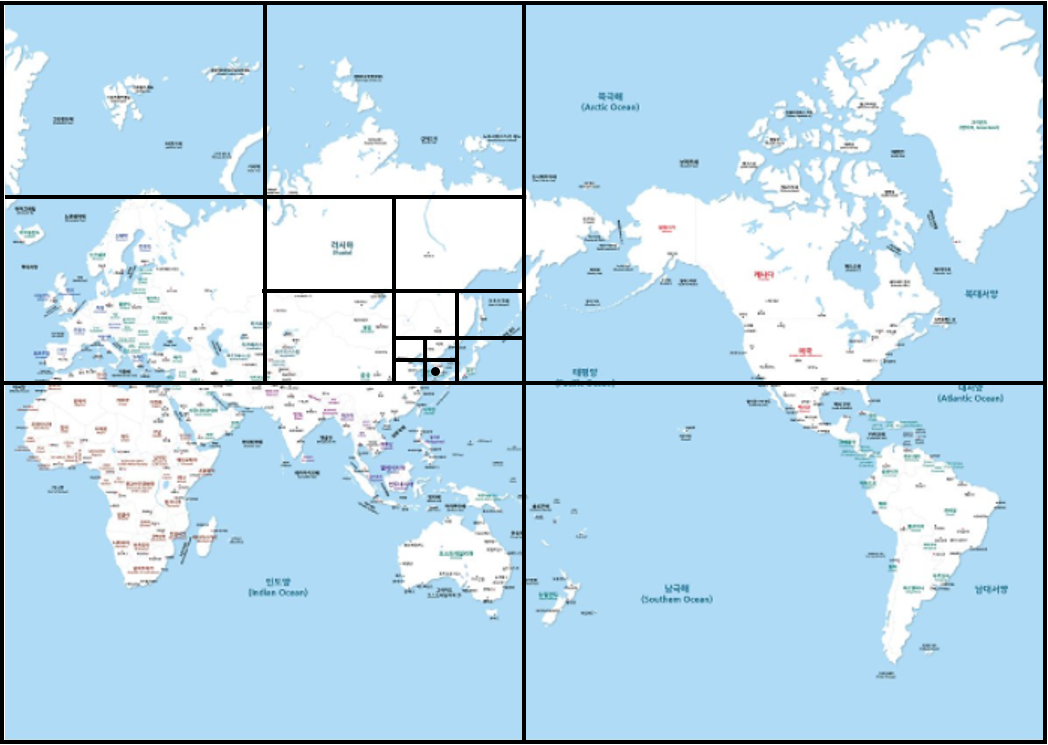
- DB에 지구의 모든 부분이 Mapping되어 있다고 생각하면 된다.
- 만약 서울을 찾는다고 했을때 위의 그림처럼 4분할로 계속 찾아나간다고 생각하면 된다.
- Location Based DB로 사용될 수 있다.
- 거대한 지형을 빠르게 탐색할 수 있다.
- Time complexity는 O(log₄N)이 되며 이는, O(N)보다 훨씬 빠르다.
'시스템 디자인' 카테고리의 다른 글
| 시스템 디자인 6주차 (0) | 2021.08.26 |
|---|---|
| 시스템 디자인 5주차 (0) | 2021.08.13 |
| 시스템 디자인 3주차 (0) | 2021.07.21 |
| 시스템 디자인 2주차 (0) | 2021.07.18 |
| CDN (0) | 2021.07.16 |