

티스토리 뷰
System Design시 고려 사항
Server - Client 통신 시 다음과 같은 예외사항이 발생할 수 있다.
- Client가 Server를 찾지 못하는 경우
- Server가 다운되어 Client의 Request를 받지 못할 경우
- Client가 다운되어 Server의 Response가 소실된 경우
- Client가 crash된 경우
이러한 예외사항을 방어하기 위해 다음을 고려할 수 있다.
- Reliability : 신뢰성
- Availability : 유용성
- Low latency : 짧은 지연시간
- Performance : 성능
- Const effective : 지속성
상황별로 네트워크 프로토콜을 TCP또는 UDP를 사용할 수 있다.
- TCP는 3way-handshake와 세그먼트를 통한 높은 신뢰성을 가지고 있고 UDP에 비해 상대적으로 느리다.
- 속도가 TCP에 비해 빠르지만 Server의 실행 여부와 관계없이 데이터를 전송하며, 서버가 다운되어 있는 상황이면 데이터가 소실된다.
Capacity Estimation
Capacity
아래의 용량 단위는 기억해두면 좋다.
- 8bits = 1byte
- 1024 bytes = 1kb
- 1024kb = 1mb
- charactor = 1byte
- int = 4byte
- timestamp = 4byte
Time
- 60 * 60 = 3600s (hour)
- 3600 * 24(1day) = 86,400s (day)
- 86,400s * 30 = 2,500,000s (month)
CPU와 Memory
CPU cycle이 1sec로 가정했을 때 그외 h/w의 속도
| type | time | sec |
| CPU cycle | 0.3ms | 1s |
| RAM | 120ms | 6m |
| SSD | 150ms | 6days |
| HDD | 10ms | 12months |
| CA (Europe latency) | 183ms | 19years |
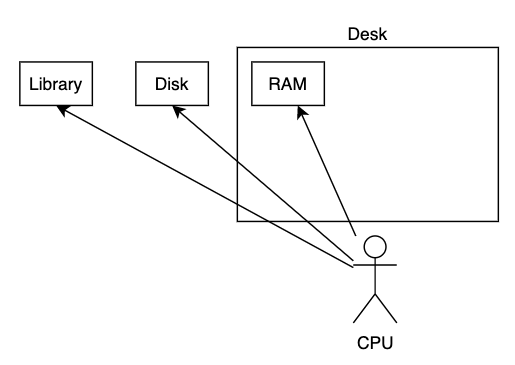
Back-end developer가 고려해야 될 부분
- 하루 총 Request 수 : 평균 DAU * reads(get) + write(post)
DAU : Daily Active Users(DAU) : 하루동안 해당 서비스를 이용한 순수 이용자 수
EX) SNS서비스 시스템을 디자인할 때
- 보통 Global 대기업에서 운영하는 서비스의 Read/Write비율을 80:20으로 가정한다.
- User1명이 하루에 30개의 게시글을 읽고, 1개의 게시글을 업로드 한다고 가정
- 1000만명의 사용자가 있다고 가정.
- 10 million DAU * 30 photos = 300 million (http method Get)
- 10 million DAU * 1 photo upload = 10 million photo (http method Post)
- 위의 가정에서 1초당 요청 수
- 300 million Get / 86400s = 3472 reads/sec
- 10 million Post / 86400s = 115 writes/sec
- 팔로워 기능이 있고 팔로워 수에 따라 게시글이 얼마나 많이 노출되는지 다를것이고, 이 비율을 20%라고 가정
- DB로 접근하는것이 아닌 Caching을 하는것이 효율적
- 하루에 발생하는 총 트래픽 => 300 milion Request * 500bytes(사진) * 0.2 = 30GB
- 위의 계산은 한 Server에 국한되며, 여러가지 예외사항을 방어하기 위해 Server를 5개로 운영(replica적용)한다고 가정
- 30GB * 5 = 150GB
이는 단순히 photo데이터만을 고려했을 경우이며, SNS서비스의 기능(영상, 포스팅, 채팅 등)에 따라 감당해야 할 트래픽의 양은 어마어마할 것이며 이를 감당하는 시스템을 디자인 하는것은 매우 중요하다.
Latency(지연시간)
- 총 지연시간
① Client -> Server
② Server -> DB
③ DB의 작업 (read / search / write)
④ DB -> Server
⑤ Server -> Client

Accessing
- 1MB를 Memory에서 순차적으로(sequencielly) 읽는다면 250ms(0.25s)
- 1MB를 SSD에서 읽는다면 1000ms(1s)
- 1MB를 HDD에서 읽을 경우 20000ms
Throughput(처리율)
- 서버가 감당할 수 있는 Request의 수

Availablity(응답성)
- Server Operating time
- availability가 100%일수는 없으며, 99%일 경우 1년에 5일(24h*5)의 시간동안 서버가 작동하지 않는다.
- HA(Highly Availability)의 기준은 99.999%이며, 이 정도의 수치는 1년에 5분동안 서버가 작동하지 않는다.
- 1년에 5분동안 작동하지 않는 것도 허용하지 않기위해 Replica(다중 서버), Redundancy(여분 서버)등의 시스템을 구축
- 서비스 수준 고려
- SLA(Service Level Agreement) : 서비스가 특정 기대에 못미쳤을 경우 고객 보상을 제공해주는 계약
- SLI(Service Level Indicators) : 서비스의 측정 가능한 특성, 시간이 정해지고 측정 가능해야 된다.
- SLO(Service Level Object) : 주어진 SLI에서 성취할 서비스 수준의 목표 또는 숫자지표
'시스템 디자인' 카테고리의 다른 글
| 시스템 디자인 5주차 (0) | 2021.08.13 |
|---|---|
| 시스템 디자인 4주차 (0) | 2021.07.31 |
| 시스템 디자인 3주차 (0) | 2021.07.21 |
| CDN (0) | 2021.07.16 |
| 시스템 디자인 (0) | 2021.07.10 |