
티스토리 뷰
Capacity Estimation
기획 단계에서 어떤 서비스를 만들고 어떠한 feature가 들어갈 지 생각해 보면, Capacity Estimation이 되어야 어느 정도 사이즈로 DB table을 만들고 Server의 크기, 분포도를 어느정도로 설정할 지 결정하는데 도움이 된다.
이는 scalable한 서비스를 만드는데 중요하다.
Cache
- Repeat : 반복 호출이 필요한 Data
- Immutability : static Data
- Computation heavy : cost가 많은 결과물
- 길찾기 알고리즘을 실행한다고 가정
- 어떤 목적지에서 다른 목적지로 이동하는 최단거리 알고리즘의 시간 복잡도가 O(n²)라고 가정
- 해당 연산을 요청을 보낼때 마다 반복한다면 Server의 부담이 커진다. (같은 응답값을 가지면서 cost가 높은 연산을 반복하므로 비효율적임)
- 한번만 계산을 한 후 이 결과를 Cache로 남겨두어 이후 연산없이 Cache로 데이터를 가져올 수 있으므로 효율적이며 Server failure가 감소할 것
- ex) 카카오맵, 구글맵에서 캐시를 통해 결과를 응답한다.
Cache 사용 예시 - 조회
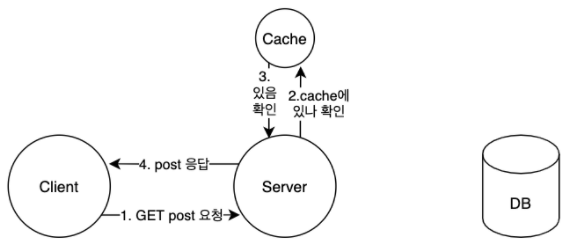
facebook에서 Cache를 사용하여 post를 조회한다고 가정.
1. Cache에 post 데이터가 없을 때 post 조회 요청을 한다면
2. Client → Server로 Request
3. Server는 Cache에 Request에 대한 Response 데이터가 Cache에 있는지 확인
4-1. Cache에 데이터가 존재하지 않는다면 해당 데이터를 DB에서 조회하여 데이터를 Server로 가져온다.
4-2. Cache에 데이터가 존재한다면 해당 데이터를 그대로 Client에 Response
5. Response할 데이터를 Cache에 저장한다.
6. Client ← Server로 Response

Cache 사용 예제 - 수정
수정요청 등 데이터 변경이 일어날 경우 Cache 메모리와 DB의 데이터 저장 시점에 관한 정책을 Cache Write Policy라고 한다.
이에 2가지 방법이 있다.
Write through
Client로 부터 수정 Request가 도착하면 Server는 Cache와 DB의 데이터를 모두 업데이트 하는 방식이다.
1. Client → Server로 수정 Request
2. Server는 우선 Cache를 업데이트
3. DB업데이트
4. Client ← Server로 Response

- Cache와 DB 데이터의 일관성(consistency)를 유지할 수 있음.
- DB에 업데이트하는 cost가 Write Back방식보다 더 높으므로 지연시간(latency)이 높음
- 데이터의 일관성을 유지하는것이 중요한 상황에서 사용할 것.
Write Back
Server는 우선 Cache를 업데이트 후 Client에 응답, 약간의 지연시간 후 Cache의 마지막 업데이트 내용을 DB에 동기화
1. Client → Server로 수정 Request
2. Server는 우선 Cache를 업데이트
3. Cache변경을 기록
4. Client ← Server로 Response
5. Server는 비동기적으로 Cache의 변경 기록을 보고 그에 맞추어 지연시간 n마다 DB 업데이트

- DB 업데이트 비용을 감소시킬 수 있다.
- 데이터의 일관성(consistency)가 Write through방식보다 떨어진다.
- 동시에 여러 Client가 Request를 보낸다면 업데이트 이전 데이터를 가져오는 위험이 있다.
- 데이터의 일관성이 중요하지 않으며 쓰기가 많을때 사용하는 것이 적절.
적절한 Cache 쓰기 정책은?
- 서비스에 따라 Write through를 사용할지 Write back을 사용할 지 결정(상황에 따라 적절히)
- ex) facebook feed : 업데이트가 바로바로 확인 되어야 할 경우 => Write through사용
- blog : 업데이트가 바로 반영되지 않아도 될 경우 => Write back 사용
캐시 사용처
- Front-end : Auth, static 파일(html, css, javascript, images, ...)
- Back-end : 많은곳에서 사용
- 하드웨어 : CPU cache L1/L2/L3
CPU cache L1/L2/L3
CPU는 메모리를 읽으며 자주 이용되는 정보를 캐시 메모리에 저장함으로써 재사용에 대한 효율을 높인다.
L은 Level의 약어이며 L1은 1차 캐시메모리이다. L1부터 순차적으로 데이터를 찾으며 데이터를 찾을때 까지 L2, L3로 순차적으로 데이터를 탐색한다.
다중 서버(Replica) 환경에서의 Cache
다중서버를 이용하고 Youtube comment system을 예시로 들어보았을 때,

Client가 "comment change"요청을 보내고, 이 요청이 서버1이 받는다면, 서버1은 해당 요청을 수행하여 DB와 Cache를 업데이트한다.
이때 업데이트 한 내용은 서버1의 cache만 변경되므로 다른 서버가 사용하는 cache는 변경이 되지 않은 상태이므로 데이터의 일관성이 떨어진다. 또한 최신 정보를 가져오기 위해 Cache가 아닌 DB를 계속 조회해야 될 상황이라면 Server의 Failure이 높아질것이다.
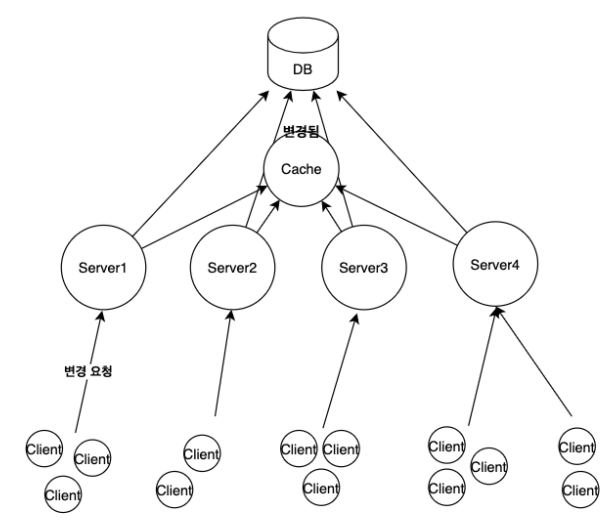
서버를 다중으로 구축하더라도, Cache 저장소는 하나만 두도록 한다.
Cache Eviction
Cache 공간이 필요할 때 어떤 데이터를 지우는 것을 의미한다.
어떤 데이터를 지울지에 대한 판단은 LRU알고리즘 또는 LFU알고리즘 등을 이용할 수 있다.
Cache는 속도를 위해 대부분 메모리를 사용하며, 메모리를 사용할 경우 메모리 용량에 대한 문제가 생기고, 이를 줄이기 위해 Eviction은 중요하다.
LRU(Least Recently Used)
Cache의 크기가 한계가 되면, 사용된지 오래된 순으로 제거한다.
LFU(Least Frequently Used)
캐시의 크기가 한계가 되면 사용된 빈도가 낮은 순서대로 제거된다.
// key는 Frequency
FrequencyTable = {
1: [M1, M2],
2: [M3],
3: [M4],
4: [M5]
}
위의 메모리 사용 빈도를 가지고 있는 Frequency Table이 있고, Cache의 용량이 가득차있다고 가정했을때,
만약 M2를 사용했다면, M2는 Frequency가 1 증가한 2에 위치하게 될 것이다.
FrequencyTable = {
1: [M1],
2: [M3, M2],
3: [M4],
4: [M5]
}
여기서 M6를 넣어야 할 경우, Cache가 가득차있으므로 사용빈도가 가장 낮은 M1을 제거한후 M6를 넣는다.
FrequencyTable = {
1: [M6],
2: [M3, M2],
3: [M4],
4: [M5]
}
Load Balancer
Forward Proxy
- Client의 IP address를 숨겨준다.
- Client의 요청을 forward proxy에 forward하면 proxy는 ip주소를 숨긴다.
- Server에서는 proxy의 ip주소가 출발지임으로 인지한다.
- 정해진 사이트만 연결하게 설정하는 등 웹 사용 환경을 제한할 수 있기 때문에 기업 내부 환경에서 많이 사용한다.
- 서버는 forward proxy서버를 통해 요청을 받아 클라이언트의 정보를 알 수 없다.

Reverse Proxy
- 일반적으로 Forward Proxy보다 Reverse Proxy를 더 많이 사용한다.
- Client는 브라우저의 도메인 입력창에 google.com을 친다면 DNS의 google.com의 실제 서버 주소가 아닌 reverse proxy의 주소가 mapping되어 있다. 따라서 Client의 Request는 reverse proxy로 우선 향하고, reverse proxy는 이 Request를 실제 google 서버로 forwarding한다.
- 내부 서버에 대한 설정으로 Load Balaning이나 Server 확장에 유리하다.
- throughput(처리율)이 높아지면 server failure가 많아지는데, 이를 방지하기 위해 요청을 분산해준다.
- Server는 감춰지므로 실제 Server의 정보를 알 수 없어서 보안상 이점이 있다.
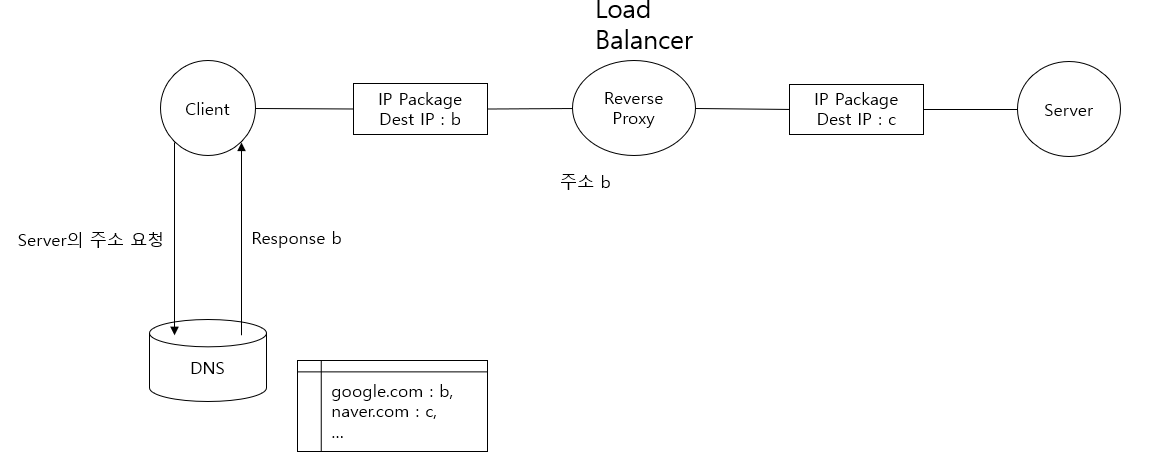
대표적으로 nginx를 통해 Load Balacing을 구현할 수 있다.
스케줄링 알고리즘
Load Balacing을 하다보면 하나의 Server에 부하가 몰릴 경우가 생길 수 있다.
이러한 상황의 방지책으로 다양한 스케줄링 알고리즘이 있다
Round Robin
- Client의 요구를 순차적으로 각 Server에 균등히 분배하여 부하를 나눈다.
- Server의 추가 삭제가 용이하다.
Weighted Round Robin
- Round Robin알고리즘에 가중치가 추가된 알고리즘이다.
- 서버별로 서로 다른 가중치를 설정할 수 있다.
'시스템 디자인' 카테고리의 다른 글
| 시스템 디자인 5주차 (0) | 2021.08.13 |
|---|---|
| 시스템 디자인 4주차 (0) | 2021.07.31 |
| 시스템 디자인 2주차 (0) | 2021.07.18 |
| CDN (0) | 2021.07.16 |
| 시스템 디자인 (0) | 2021.07.10 |