
티스토리 뷰
Map Reducer
대용량 데이터 처리를 위한 분산 프로그래밍 모델이다.
예를 들어 데이터를 분산하여 저장한다면, 검색을 어떻게 할 수 있을까?
여러개의 Data Node들에 저장되어있는 데이터를 한 곳으로 가져와 분석/처리를 한다고 가정해볼때,
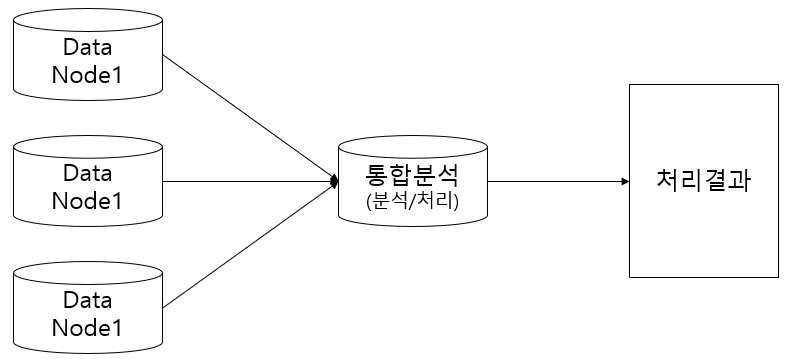
이 경우 작업(분석/처리)는 한곳에서 이루어지기 때문에 처리속도가 매우 느릴 것이다.
나누어 저장하는 것뿐 아니라 일을 나누어 처리해야 하기 때문에 의미가 없다.
100TB 데이터를 (초당 100mb를 처리하는) 컴퓨터 1대에서 처리한다면 약 12일이 걸린다.
그런데 1000대 컴퓨터에서 분산 처리한다면 17분 내 처리가 가능하다.
Map Reducer는 데이터를 나누어 저장할 뿐만아니라 작업도 분산처리가 가능하도록 한다.
개념
Map과 Reduce를 합친 의미로, 여러 대의 서버가 하나의 시스템처럼 작동하는 컴퓨터 클러스터 환경에서, 대용량 데이터 처리를 지원하는 기술이다.
흩어져 있는 데이터를 수직화한다.
- 데이터를 각각 종류별로 모은다, 데이터를 분석한다 (Map)
- 분석한 데이터를 filtering과 sorting을 거쳐 데이터를 추출하는 분산처리 기술이다. (Reduce)
- Spliting -> Mapping -> Shuffling -> Reducing의 과정을 거친다.
- map과 reduce는 단순한 function으로써, 같은 input에 대하여 같은 결과를 반환한다.
Map
- 흩어진 데이터를 Key, Value 형태로 연관성 있는 데이터 분류로 묶는다.
- 데이터 처리를할 때, 데이터가 분산된 상태에서 이를 매핑시켜준다. → map이라는 function을 정의하고, 모든 노드에 적용시킨다.
- 각각 관련된 것을 분산 컴퓨터에서 처리한다. (key, value쌍 도출)
Reduce
- 데이터를 Filtering / Sorting하여, Key/Value형태로 도출화 한 작업에서 중복되는 데이터를 제거, 필요한 데이터를 추출하여 데이터를 경량화 한다.
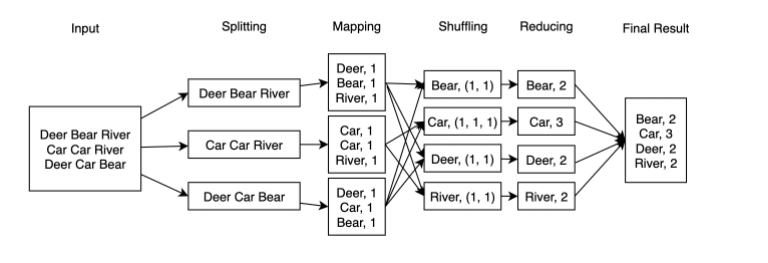
Map Reduce 오픈소스 Framework로 Hadoop이 있다.
Face Recognition
Map Reduce 모델을 이용한 face recognition프로그램
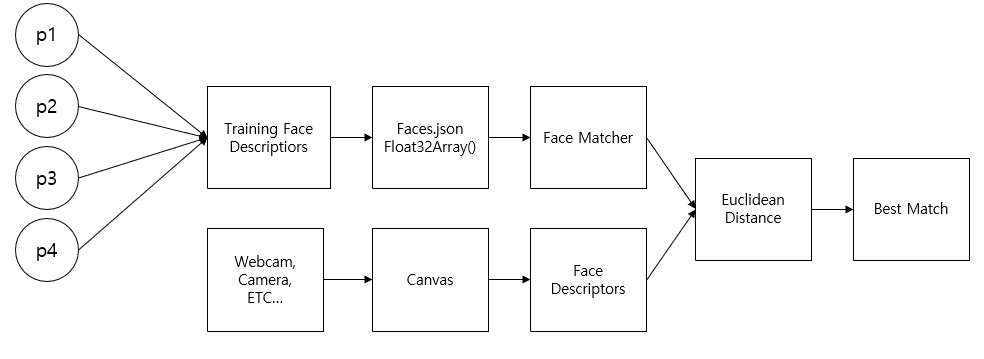
- 웹캠이 사람을 인식할 때 canvas에 웹켐이 읽은 형상을 그린다.
- face descriptor가 나타나며 이를 Euclidean Distance를 통해 해당 형상이 데이터베이스에 있는 best match를 실시간으로 출력한다.
'시스템 디자인' 카테고리의 다른 글
| 시스템 디자인 7주차 (0) | 2021.08.30 |
|---|---|
| 시스템 디자인 6주차 (0) | 2021.08.26 |
| 시스템 디자인 5주차 (0) | 2021.08.13 |
| 시스템 디자인 4주차 (0) | 2021.07.31 |
| 시스템 디자인 3주차 (0) | 2021.07.21 |