
티스토리 뷰
문자열 검색 알고리즘
문자열 검색 알고리즘은 자동완성, ctrl+f를 눌렀을 때 특정 단어를 찾을 경우 등 수많은 곳에서 활용된다.
KMP알고리즘은 이 알고리즘을 개발한 사람의 이름을 따서 (Knuth, Morris, Prett) KMP알고리즘이라고 한다.
2개의 문자열간 일치하는 패턴을 확인하는 알고리즘이다.
만약 하나의 문자열과 다른 문자열을 비교할때 가장 단순하게는 문자열 하나하나를 비교해나가는 것일것이다.
단순 검색
문자열1은 "ABABCABCDE"이고 문자열2는 "ABCDE"라고 하자
문자열1을 기준으로 문자열2를 맞추어 나가면서 일치하는 문자열을 찾을때까지 순회할 수 있다.
1번째 비교
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| A | B | A | B | C | A | B | C | D | E |
| A | B | C | D | E |
2번째 비교
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| A | B | A | B | C | A | B | C | D | E |
| A | B | C | D | E |
3번째 비교
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| A | B | A | B | C | A | B | C | D | E |
| A | B | C | D | E |
4번째 비교
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| A | B | A | B | C | A | B | C | D | E |
| A | B | C | D | E |
5번째 비교
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| A | B | A | B | C | A | B | C | D | E |
| A | B | C | D | E |
6번째 비교
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| A | B | A | B | C | A | B | C | D | E |
| A | B | C | D | E |
단순하게 한칸씩 이동하며 문자열이 일치하는지 비교할 수 있다.
문자열을 한칸씩 이동하여 하나하나 비교하는 코드이다.
void bruteForce(string str, string pattern) {
for (int i = 0; i < (int)str.size() - (int)pattern.size() + 1; i++) {
bool find = true;
for (int j = 0; j < (int)pattern.size(); j++) {
cout << str[i + j] << pattern[j] << endl;
if (str[i + j] != pattern[j]) {
find = false;
}
}
if (find == true) {
cout << "[" << i << "]번째에서 발견" << "\n";
return;
}
}
}한칸한칸 이동한다면 Time Complexity는 O(n*m)이 된다.
KMP알고리즘
이렇게 한칸한칸 비교해 나갈 수 있지만 조금 불필요한 연산이 생긴다.
위의 문자열 비교 표에서 1번째 비교에서 2개의 문자열이 일치하지 않지만, "AB"가 동일하다는 것을 확인했고, 2번째 비교는 불필요한 비교가 된다.
여기서 1번째 비교에서 얻은 정보를 가지고 2번째 비교와 같은 불필요한 연산을 건너뛰도록 하여 검색 속도를 늘리는 것이 KMP알고리즘의 핵심이다.
KMP알고리즘에서는 비교할 문자열에 대한 정보가 필요하다.
문자열1을 "ABABCABCDE"라고 하고, 문자열2를 "ABCDE"라고 하자
두 문자열 사이 일치했던 문자열 패턴에 대한 정보를 저장해놓을 필요가 있다. 이는 숫자형 배열로 나타낼 수 있다.
number배열을 완성하기 위해 2개의 포인터를 준비한다. i는 1번째 문자를 가리키고 j는 0번째 문자를 가리킨다.
문자열을 순회하며 number배열을 완성해보자.
1. i번째 문자 B와 j번째 문자 A는 다르므로 넘어간다.

2. i번째 문자와 j번째 문자가 같으므로 j를 1증가시킨 후 j를 number[i]에 저장한다.


3. i번째 문자B와 j번째 문자B가 같으므로 j를 1증가시킨 후 j를 number[i]에 저장한다.
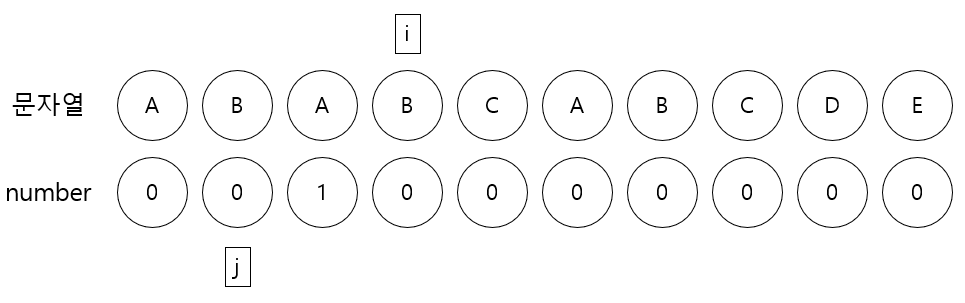
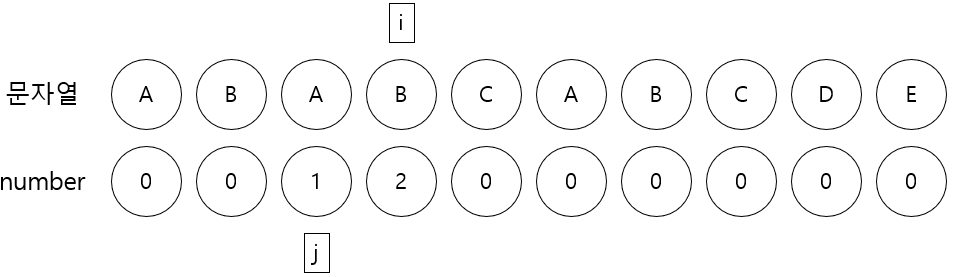
4. i번째 문자C와 j번째 문자A가 다르므로 j를 이동시키는데 여기서 j가 0보다 크고 i가 가리키는 문자와 j가 가리키는 문자가 다를동안 j에 number[j-1]를 할당한다.


5. i가 가리키는 문자 A와 j가 가리키는 문자 A가 같으므로 j를 1증가한 후 number[i]에 j를 저장한다.


6. i가 가리키는 문자 B와 j가 가리키는 문자 B가 같으므로 j를 1증가시킨 후 number[i]에 j를 저장한다.


7. i번째 문자C와 j번째 문자A가 다르므로 j를 이동시킨다.


8. i번째 문자 D와 j번째 문자 A가 다르므로 넘어간다.

9. i번째 문자 E와 j번째 문자 A가 다르므로 넘어간다.

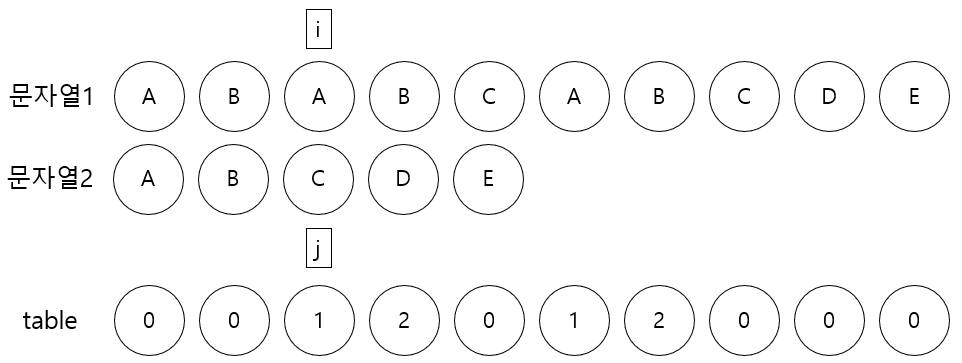
number배열이 완성된다
number 배열을 table이라고 하며, table배열을 완성시키는 함수를 makeTable이라고 했을때
void makeTable(string str, vector<int>& table) {
for (int i = 1; i < str.size(); i++) {
int j = table[i - 1];
while (j > 0 && str[j] != str[i]) {
j = table[j - 1];
}
if (str[j] == str[i]) {
j++;
}
table[i] = j;
}
}
이렇게 완성된 문자열 정보를 담은 table을 이용하여 kmp알고리즘을 실행한다.
이제 kmp알고리즘을 실행해보자.
kmp 알고리즘 실행
문자열1은 정보를 저장해 둔 "ABABCABCDE", 문자열2는 "ABCDE"라고 하자.
그리고 i = 0, j = 0이라고 하고, 문자열1에서 문자열2를 찾아보자
i는 문자열1을 순회하는 포인터이고 j는 문자열2를 순회하는 포인터라고 하자.
포인터 i는 꾸준히 증가시키며, 포인터 j는 문자열1[i]와 문자열2[j]의 상태에 따라 j의 포인터 이동을 달리한다.
1. 문자열1[i] A와 문자열2[j] A가 같다.
이때 j가 문자열2 길이 - 1가 같을 경우 문자열1에서 문자열2를 찾은것이다. 하지만 j는 0이고, 문자열2 길이 - 1은 4로 다르다. 그래서 그냥 j증가만 시킨다.

2. 문자열1[i] B와 문자열2[j] B가 같으므로 j를 증가시킨다.

3. 문자열1[i] A와 문자열2[j] C가 다르다.
여기서 j를 이동시켜야 하는데 위의 table에서 j를 이동시키는 방법과 비슷하다.
문자열1[i]와 문자열2[j]가 가리키는 문자가 다를동안 j에 table[j-1]을 넣는다, 즉 j는 0이 된다.

4. 문자열1[i] B와 문자열2[j] A는 다르므로 그냥 넘어간다.

5. 문자열1[i] C와 문자열2[j] A는 다르므로 그냥 넘어간다.

6. 문자열1[i] A와 문자열2[j] A는 같다.
하지만 j는 0으로 문자열2길이 - 1과 다르다. 그러므로 j를 증가시킨다.
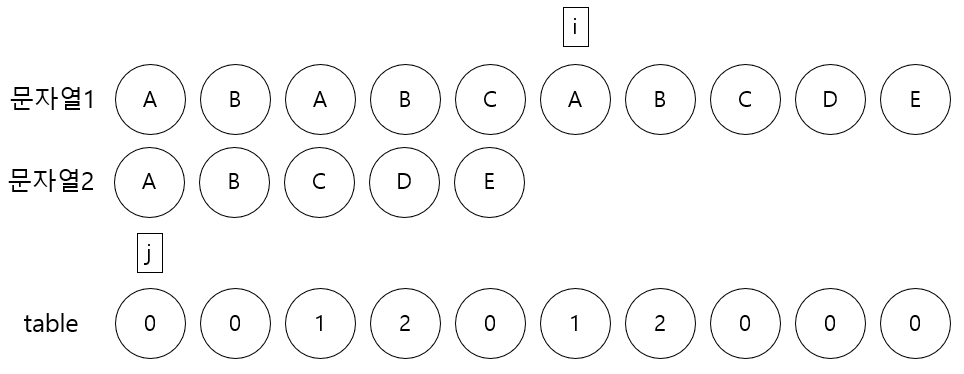
7. 문자열1[i] B와 문자열2[j] B는 같다.
하지만 j는 1으로 문자열2길이 - 1과 다르다. 그러므로 j를 증가시킨다.

8. 문자열1[i] C와 문자열2[j] C는 같다.
하지만 j는 2로 문자열2길이 - 1과 다르다. 그러므로 j를 증가시킨다.
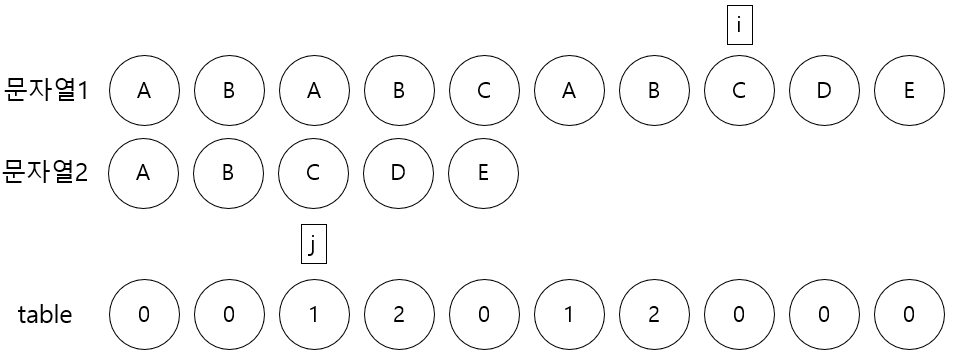
9. 문자열1[i] D와 문자열2[j] D는 같다.
하지만 j는 3으로 문자열2길이 - 1과 다르다. 그러므로 j를 증가시킨다.

9. 문자열1[i] E와 문자열2[j] E는 같다.
그리고 j는 4로 문자열2길이 - 1과 같아지므로 문자열1에서 문자열2를 찾아낸것이다.

즉, (i - 문자열2길이 + 1)번째에서 찾은 것이다.
이러한 과정이 헷갈릴수도 있다.
여기서 조금 다른 예제를 이용하여 문자열1에서 문자열2를 못찾은 경우를 생각해보자.
만약 문자열1이 "ABABCABCDE"이고, 문자열2가 "ABCDF"라고 하자.
위의 과정을 거쳐 i는 문자열1의 마지막인 E를 가리키고 있고, j는 문자열2의 마지막인 F를 가리키고 있다고 해보자.

문자열[i]와 문자열[j]가 다르므로 j를 이동시켜야 한다.
j가 0보다 크고 문자열1[i]와 문자열2[j]가 다를 동안 j = table[j - 1]을 반복해야 된다.
그렇다면 j는 1을 거쳐 0이 될것이다.

즉 문자열1의 i번째 부터 문자열2를 새로 찾아야 되는 상태가 된다.
조금 더 다른 예시로 하여, 문자열1이 "ABABCABCDEABCDF"이고 문자열2가 "ABCDF"를 생각해보자
i가 문자열1의 E를 가리키고 있고(i = 9) j가 문자열2의 A를 가리키고있다. (j = 0) 이는 위의 사진과 같은 상태이다.
i는 10부터 시작하고 j는 0부터 시작하여 같은 문자열 패턴을 찾아낼 수 있게 된다.
코드로 작성하면 아래와 같다.
void kmp(string str, string pattern, vector<int>& table) {
int strLen = str.size(), patLen = pattern.size();
int j = 0;
for (int i = 0; i < strLen; i++) {
while (j > 0 && str[i] != pattern[j]) {
j = table[j - 1];
}
if (str[i] == pattern[j]) {
if (j == patLen - 1) {
cout << "[" << i - patLen + 1 << "]번째에서 발견" << endl;
j = table[j];
}
else j++;
}
}
}문자열1을 str이라고 하고 문자열2를 pattern이라고 하자.
str[i]와 pattern[j]가 같다고 했을때, j는 pattern.size() - 1과 같으면 발견, 다르면 j를 증가시킨다.
if (str[i] == pattern[j]) {
if (j == patLen - 1) {
cout << "[" << i - patLen + 1 << "]번째에서 발견" << endl;
j = table[j];
}
else j++;
}str[i]와 pattern[j]가 다르다고 했을때, j는 0보다 크고, str[i]와 pattern[j]가 다를동안 j에 table[j - 1]을 넣는다.
while (j > 0 && str[i] != pattern[j]) {
j = table[j - 1];
}
KMP알고리즘 실행을 위해, 전체 코드로 작성하면 아래와 같다.
#include<iostream>
#include<vector>
using namespace std;
void makeTable(string str, vector<int>& table) {
for (int i = 1; i < str.size(); i++) {
int j = table[i - 1];
while (j > 0 && str[j] != str[i]) {
j = table[j - 1];
}
if (str[j] == str[i]) j++;
table[i] = j;
}
}
void kmp(string str, string pattern, vector<int>& table) {
int strLen = str.size(), patLen = pattern.size();
int j = 0;
for (int i = 0; i < strLen; i++) {
while (j > 0 && str[i] != pattern[j]) {
j = table[j - 1];
}
if (str[i] == pattern[j]) {
if (j == patLen - 1) {
cout << "[" << i - patLen + 1 << "]번째에서 발견" << endl;
j = table[j];
}
else j++;
}
}
}'Computer Science > 알고리즘_자료구조' 카테고리의 다른 글
| [알고리즘] Dijkstra, 다익스트라 알고리즘 (0) | 2021.09.13 |
|---|---|
| [알고리즘] 정렬알고리즘(2) - bubble sort, 버블정렬 (0) | 2021.09.04 |
| [알고리즘] 정렬 알고리즘(1) - selection sort, 선택정렬 (0) | 2021.07.02 |
| [알고리즘] Divide and conquer, 분할 정복 알고리즘 (0) | 2021.06.20 |
| [자료구조] BST(Binary Search Tree, 이진탐색트리) (0) | 2021.06.17 |